Tænk over det. Hvorfor opretter du en hjemmeside? For at dine potentielle kunder eller publikum nemt kan finde dig, og for at du kan skille dig ud blandt konkurrenterne, ikke? Hvordan bliver dit indhold faktisk set? Bliver alt indholdet på din side altid set?
Hvorfor du skal finde alle siderne på din hjemmeside
Det er muligt, at sider, der indeholder værdifuld information, som faktisk [skal] ses, slet ikke bliver set. Hvis dette er tilfældet for din hjemmeside, så mister du sandsynligvis betydelig trafik eller endda potentielle kunder.
Der kunne også være sider, der sjældent ses, og når de gør, rammer brugere/besøgende/potentielle kunder en blindgyde, da de ikke kan få adgang til andre sider. De kan kun forlade. Dette er lige så slemt som de sider, der aldrig ses. Google vil begynde at bemærke de høje afvisningsprocenter og stille spørgsmålstegn ved din sides troværdighed. Dette vil få dine websider til at rangere lavere og lavere.
Hvordan dit indhold faktisk bliver set

For brugere, besøgende eller potentielle kunder at se dit indhold, skal crawling og indeksering udføres og udføres hyppigt. Hvad er crawling og indeksering?
Hvad er crawling og indeksering?
For Google at vise dit indhold til brugere/besøgende/potentielle kunder, skal det først vide, at indholdet eksisterer. Hvordan dette sker, er via crawling. Dette er, når søgemaskiner søger efter nyt indhold og tilføjer det til sin database af allerede eksisterende indhold.
Hvad gør kravling mulig?
- Links
- Sitemaps
- Content Management Systems (CMS - Wix, Blogger)
Links:
Når du tilføjer et link fra en eksisterende side til en anden ny side, for eksempel via ankertekst, er søgemaskinebots eller edderkopper i stand til at følge den nye side og tilføje den til Googles 'database' til fremtidig reference.
Sitemaps:
Disse er også kendt som XML Sitemaps. Her indsender webstedsejeren en liste over alle deres sider til søgemaskinen. Webmasteren kan også inkludere detaljer som den sidste ændringsdato. Siderne bliver derefter crawlet og tilføjet til ‘databasen’. Dette er dog ikke i realtid. Dine nye sider eller indhold vil ikke blive crawlet, så snart du indsender dit sitemap. Crawling kan ske efter dage eller uger.
De fleste sider, der bruger et Content Management System (CMS), genererer disse automatisk, så det er en smule af en genvej. Den eneste gang en side måske ikke har sitemapet genereret, er hvis du har oprettet et websted fra bunden.
CMS:
Hvis din hjemmeside drives af et CMS som Blogger eller Wix, er hostingudbyderen (i dette tilfælde CMS'et) i stand til at 'fortælle søgemaskiner at crawle nye sider eller indhold på din hjemmeside.'
Her er nogle oplysninger til at hjælpe dig med processen:
Tilføjelse af et sitemap til WordPress
Hvad er indeksering?
Indeksering i enkle termer er tilføjelsen af de gennemsøgte sider og indhold til Googles 'database', som faktisk omtales som Googles indeks.
Før indholdet og siderne tilføjes til indekset, forsøger søgemaskinernes bots at forstå siden og indholdet deri. De går endda videre til at katalogisere filer som billeder og videoer.
Dette er grunden til, at on-page SEO som webmaster er praktisk (sidetitler, overskrifter og brug af alt-tekst, blandt andet). Når din side eller sider har disse aspekter, bliver det lettere for Google at 'forstå' dit indhold, katalogisere det passende og indeksere det korrekt.
Brug af robots.txt
Nogle gange ønsker du måske ikke, at nogle sider eller dele af et website indekseres. Du skal give direktiver til søgemaskinebots. Brug af sådanne direktiver gør også crawling og indeksering lettere, da der er færre sider, der crawles. Læs mere om robots.txt her.

Brug af ‘noindex’
Du kan også bruge denne anden direktiv, hvis der er sider, som du ikke ønsker skal vises i søgeresultaterne. Læs mere om noindex.
Før du begynder at tilføje noindex, vil du gerne identificere alle dine sider, så du kan rydde op på dit site og gøre det lettere for crawlers at crawle og indeksere dit site korrekt.
Hvad er nogle grunde til, at du skal finde alle dine sider?
Hvad er [orphan pages]?
En "forældreløs side" kan defineres som en, der ikke har nogen links fra andre sider på dit websted. Dette gør det næsten umuligt for disse sider at blive fundet af søgemaskinebots, og desuden af brugere. Hvis bots ikke kan finde siden, vil de ikke vise den i søgeresultaterne, hvilket yderligere reducerer chancerne for, at brugerne finder den.
Hvordan opstår forældreløse sider?
Forældreløse sider kan skyldes et forsøg på at holde indhold privat, syntaksfejl, slåfejl, duplikeret indhold eller udløbet indhold, der ikke blev linket. Her er flere måder:
- Test sider, der blev brugt til A/B testning, og som aldrig blev deaktiveret
- Landingssider, der var baseret på en sæson, for eksempel, jul, Thanksgiving eller påske
- ‘Glemte’ sider som et resultat af site migration
Hvad med blindgyde-sider?
I modsætning til forældreløse sider har dead-end sider links fra andre sider på hjemmesiden, men linker ikke til andre eksterne sider. Eksempler på dead-end sider inkluderer takkesider, servicesider uden call to actions og “intet fundet” sider, når brugere søger efter noget via søgefunktionen.
Når du har blindgyde-sider, har folk, der besøger dem, kun to muligheder: at forlade siden eller gå tilbage til den forrige side. Det betyder, at du mister betydelig trafik, især hvis disse sider tilfældigvis er 'hovedsider' på dit website. Endnu værre, brugerne bliver enten frustrerede, forvirrede eller undrende, 'hvad nu'?
Hvis brugere forlader din side og føler sig frustrerede, forvirrede eller med nogen negative følelser, er de aldrig tilbøjelige til at komme tilbage, ligesom utilfredse kunder aldrig er tilbøjelige til at købe fra et brand igen.
Hvor kommer [dead-end] sider fra?
Dead end-sider er et resultat af sider uden opfordringer til handling. Et eksempel her ville være en om-side, der henviser til de tjenester, som din virksomhed tilbyder, men som ikke har noget link til disse tjenester. Når læseren forstår, hvad der driver din virksomhed, de værdier, du opretholder, hvordan virksomheden blev grundlagt, og de tjenester, du tilbyder, og allerede er begejstret, skal du fortælle dem, hvad de skal gøre næste gang.
En simpel opfordring til handling-knap 'se vores tjenester' vil gøre jobbet. Sørg for, at knappen, når den klikkes, faktisk åbner op til tjenestesiden. Du ønsker ikke, at brugeren bliver præsenteret for en 404, hvilket også vil efterlade ham/hende frustreret.

Hvad er skjulte sider?
Skjulte sider er dem, der ikke er tilgængelige via en menu eller navigation. Selvom en besøgende måske kan se dem, især gennem ankertekst eller indgående links, kan de være svære at finde.
Sider, der falder ind under kategorisektionen, er sandsynligvis også skjulte sider, da de er placeret i admin-panelet. Søgemaskinen vil muligvis aldrig kunne få adgang til dem, da de ikke får adgang til information, der er gemt i databaser.
Skjulte sider kan også opstå fra sider, der aldrig blev tilføjet til webstedets sitemap, men som findes på serveren.
Skal alle skjulte sider fjernes?
Ikke rigtig. Der er skjulte sider, der er absolut nødvendige, og som aldrig bør være tilgængelige fra dine navigationer. Lad os se på eksempler:
Tilmeldinger til nyhedsbrev
Du kan have en side, der beskriver fordelene ved at tilmelde sig nyhedsbrevet, hvor ofte brugerne kan forvente at modtage det, eller en grafik, der viser nyhedsbrevet (eller tidligere nyhedsbrev). Husk også at inkludere tilmeldingslinket.
Sider, der indeholder brugeroplysninger
Sider, der kræver, at brugerne deler deres oplysninger, bør bestemt være skjult. Brugere skal oprette konti, før de kan få adgang til dem. Nyhedsbrevstilmeldinger kan også kategoriseres her.
Hvordan man finder skjulte sider
Som vi nævnte, kan du finde skjulte sider ved hjælp af alle de metoder, der bruges til at finde forældreløse eller blindgyde sider. Lad os udforske et par flere.
Brug af robots.txt
Skjulte sider er meget sandsynligt skjult fra søgemaskiner via robots.txt. For at få adgang til en sides robots.txt, skriv [domænenavn]/robots.txt i en browser og tryk enter. Erstat 'domænenavn' med din sides domænenavn. Hold øje med indgange, der begynder med 'disallow' eller 'nofollow'.
Manuelt finde dem
Hvis du sælger produkter via din hjemmeside for eksempel, og mistænker at en af dine produktkategorier måske er skjult, kan du manuelt lede efter den. For at gøre dette, kopier og indsæt en anden produkts URL og rediger den derefter. Hvis du ikke finder den, så havde du ret!.
Hvad hvis du ingen idé har om, hvad de skjulte sider kunne være? Hvis du organiserer din hjemmeside i mapper, kan du tilføje dit domænenavn/mappe-navn til en sides browser og navigere gennem siderne og undermapperne.
Når du har fundet dine skjulte sider (og de behøver ikke at forblive skjulte som diskuteret ovenfor), skal du tilføje dem til dit sitemap og indsende en crawl-anmodning.
Hvordan finder du alle siderne på dit websted
Du skal finde alle dine websider for at vide, hvilke der er blindgyder eller forældreløse. Lad os udforske de forskellige måder at opnå dette på:
Brug af din sitemap-fil
Vi har allerede kigget på sitemaps. Dit sitemap vil være nyttigt, når du analyserer alle dine websider. Hvis du ikke har et sitemap, kan du bruge en sitemap generator til at generere et for dig. Alt du skal gøre er at indtaste dit domænenavn, og sitemappet vil blive genereret for dig.
Brug af dit CMS
Hvis dit site er drevet af et content management system (CMS) som WordPress, og dit sitemap ikke indeholder alle links, er det muligt at generere listen over alle dine websider fra CMS'et. For at gøre dette, brug en plugin som Export All URLs.
Brug af en log
En log over alle de sider, der serveres til besøgende, er også praktisk. For at få adgang til loggen, log ind på din cPanel, og find derefter ‘raw log files’. Alternativt kan du bede din hostingudbyder om at dele den. På denne måde kan du se de mest besøgte sider, de aldrig besøgte sider og dem med de højeste frafaldsprocenter. Sider med høje afvisningsprocenter eller ingen besøgende kunne være blindgyder eller forældreløse sider.
Brug af Google Analytics
Her er trinene at følge:
Trin 1: Log ind på din Analytics-side.
Trin 2: Gå til ‘adfærd’ derefter ‘webstedsindhold’
Trin 3: Gå til 'alle sider'
Trin 4: Rul til bunden og vælg til højre 'vis rækker'
Trin 5: Vælg 500 eller 1000 afhængigt af hvor mange sider du vil estimere, at din side har
Trin 6: Rul op og vælg 'eksport' øverst til højre
Trin 7: Vælg ‘eksporter som .xlsx’ (excel)
Trin 8: Når excel er eksporteret, vælg 'dataset 1'
Trin 9: Sorter efter ‘unikke sidevisninger’.
Trin 10: Slet alle andre rækker og kolonner bortset fra den med dine URL'er
Trin 11: Brug denne formel på den anden kolonne:
=KONKATENERE(“http://domain.com,A1)
Trin 12: Erstat domænet med dit websteds domæne. Træk formlen, så den også anvendes på de andre celler.
Du har nu alle dine URL'er.
Hvis du vil konvertere dem til hyperlinks for nemt at kunne klikke og få adgang til dem, når du søger efter noget, gå videre til trin 13.
Trin 13: Brug denne formel på den tredje række:
=HYPERLINK(B1)
Træk formlen, så den også anvendes på de andre celler.
Manuelt indtastning i Googles søgeforespørgsel
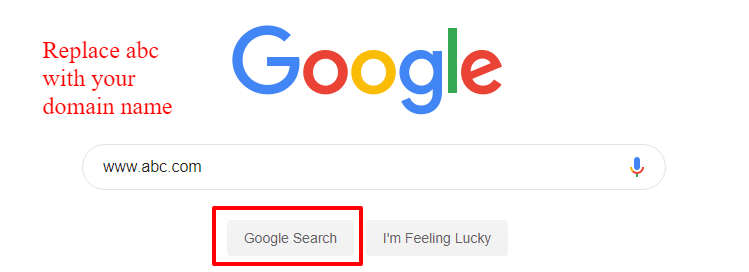
Du kan også indtaste dette site: www.abc.com i Googles søgeforespørgsel. Erstat ‘abc’ med dit domænenavn. Du vil få søgeresultater med alle de URL'er, som Google har crawlet og indekseret, inklusive billeder, links til omtaler på andre sites og endda hashtags, som dit brand kan være forbundet med.
Du kan derefter manuelt kopiere hver enkelt og indsætte dem i et excel-regneark.
Hvad gør du så med din URL-liste?
På dette tidspunkt spekulerer du måske på, hvad du skal gøre med din URL-liste. Lad os se på de tilgængelige muligheder:
Manuel sammenligning med logdata
En af mulighederne ville være manuelt at sammenligne din URL-liste med CMS-loggen og identificere de sider, der ser ud til slet ikke at have nogen trafik, eller som ser ud til at have de højeste afvisningsprocenter. Du kan derefter bruge et værktøj som vores til at tjekke for indgående og udgående links for hver af de sider, som du mistænker for at være forældreløse eller blindgyder.
En anden tilgang er at downloade alle dine URL'er som en .xlsx-fil (excel) og din log også. Sammenlign dem side om side (i to kolonner for eksempel) og brug derefter 'fjern dubletter' i excel. Følg trin for trin instruktionerne. Ved slutningen af processen vil du kun have forældreløse og blindgyde-sider tilbage.
Den tredje sammenligningsmetode er at kopiere to datasæt - din log og URL-liste til Google Sheets. Dette giver dig mulighed for at bruge denne formel: =VLOOKUP(A1, A: B,2,) til at slå URL'er op, der er til stede i din URL-liste, men ikke på din log. De manglende sider (gengivet som N/A) skal fortolkes som forældreløse sider. Sørg for, at logdataene er i den første eller venstre kolonne.
Brug af værktøjer til webcrawl
Den anden mulighed ville være at indlæse din URL-liste på værktøjer, der kan udføre site-crawls, vente på, at de crawler sitet, og derefter kopiere og indsætte dine URL'er på et regneark, før du analyserer dem en efter en og forsøger at finde ud af, hvilke der er [orphan] eller [dead end].
Disse to muligheder kan være tidskrævende, især hvis du har mange sider på dit websted, ikke?
Nå, hvad med et værktøj, der ikke kun finder alle dine URL'er, men også giver dig mulighed for at filtrere dem og viser deres status (så du ved, hvilke der er blindgyder eller forældreløse?). Med andre ord, hvis du vil have en genvej til at finde alle dine siders sider SEOptimer's SEO Crawl Tool.
SEOptimer's SEO Crawl Værktøj
Dette værktøj giver dig mulighed for at få adgang til alle dine sider på dit websted. Du kan starte med at gå til “Website Crawls” og indtaste din websteds-url. Tryk på “Crawl”
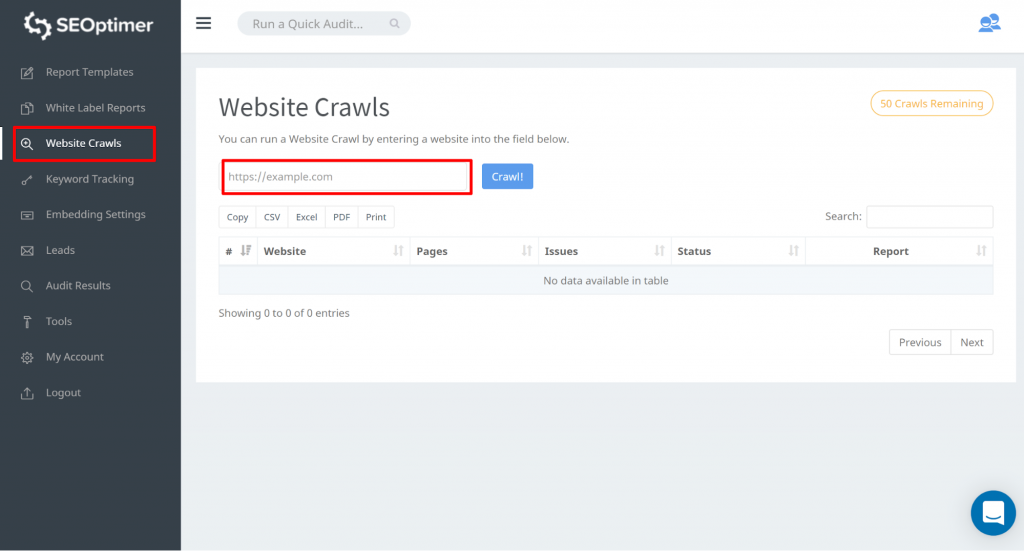
Når gennemgangen er færdig, kan du klikke på “Se rapport”:
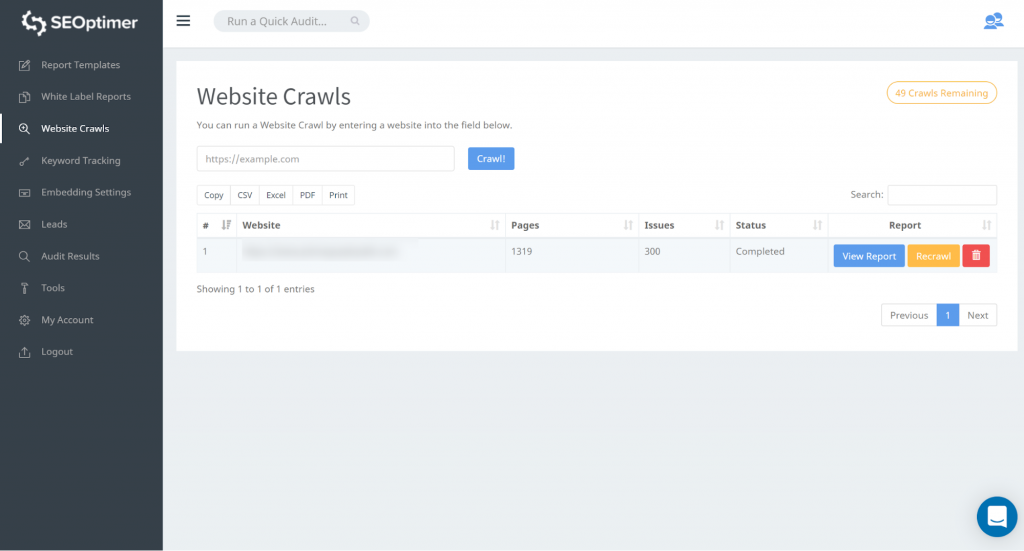
Vores crawl-værktøj vil opdage alle siderne på din hjemmeside og liste dem i sektionen “Side fundet” af crawlen.
Du kan identificere “404 Error” problemer på vores “Issues Found” lige under sektionen “Pages Found”:
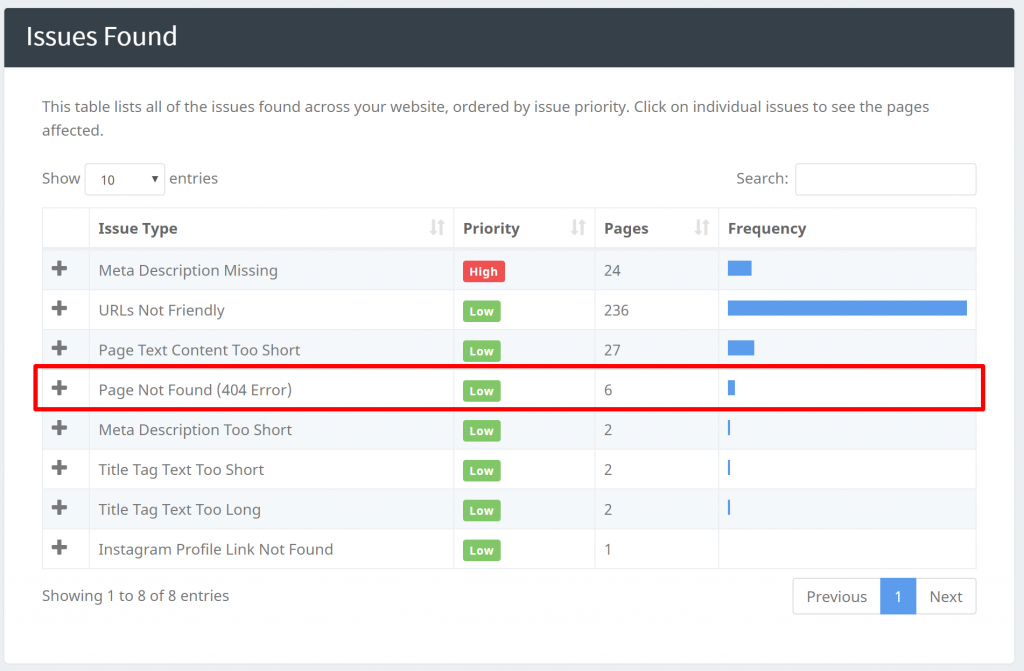
Vores crawlere kan identificere andre problemer som at finde sider med manglende [Titel], [Meta Beskrivelser], osv. Når du har fundet alle dine sider, kan du begynde at filtrere og arbejde på de aktuelle problemer.
Afslutningsvis
I denne artikel har vi set på, hvordan man finder alle siderne på dit websted, og hvorfor det er vigtigt. Vi har også udforsket begreber som forældreløse og blindgyde-sider samt skjulte sider. Vi har differentieret hver enkelt, hvordan man identificerer hver blandt dine URL'er. Der er ikke noget bedre tidspunkt at finde ud af, om du mister noget på grund af skjulte, forældreløse eller blindgyde-sider.